Challenges to recruiting population representative samples of female sex workers in China using Respondent Driven Sampling
Giovanna Merli, James Moody, Jeffrey Smith, Jing Li, Sharon Weir, and Xiangsheng Chen, 2015
This paper takes advantage of unique scenario where the same population was sampled via a fairly traditional, venue-based, random sampling procedure and respondent-driven sampling (RDS) in order to assess the validity of the assumptions underlying RDS inference. Two basic assumptions underlying inference and estimation from RDS samples is that in the referral process, each participants’ probability of being sampled is proportionate to their degree, and the RDS has equal probability of proceeding anywhere across the network, conditional on the degree of its members.
The context of this paper is the sampling of female sex workers in a relatively small geographic area in China. There are various tiers of sex workers who work in different locations. Some work at hotels, others at bars, and some on the street. These different locations lead to spatial clustering which could threaten the assumption that an individual’s degree is the only thing that determines their probability of being sampled. Their spatial proximity to recruiters may also play a role.
Using the RDS and venue-based samples, the authors first develop a set of simulations that try to decompose the constraints place on the true RDS data collection process. They vary the strength of geographic constraints on the RDS process and whether the the seeds and referral patterns should mimmick the observed patterns in size, demographic characteristics, and branching structure. Here are the results:
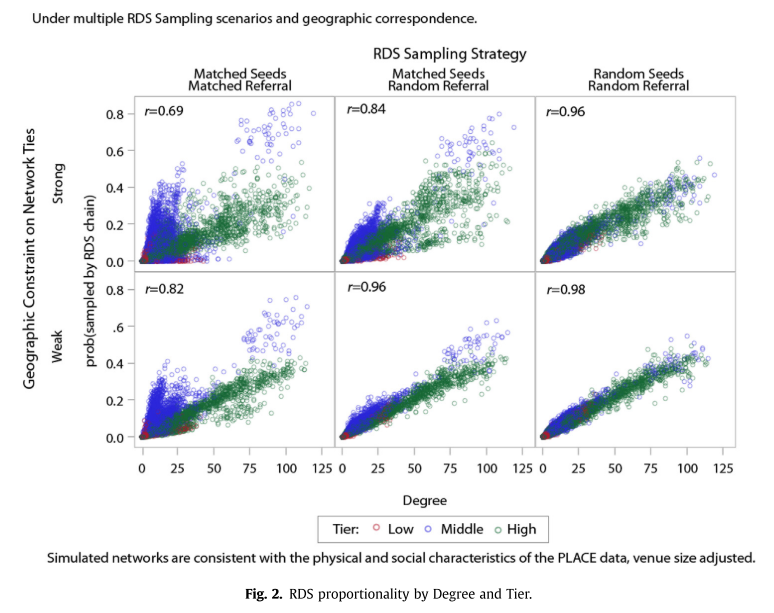
For all of these plots, a straight diagonal line with a correlation close to 1 is desired, as this indicates a strong relationship between probability of being sampled and node degree. The base model is on the right. It randomly samples seeds and referrals from the population. Under these conditions, a node’s probability of being sampled does not depend on the extent to which geography constrains referral (weak constraint on the bottom panels, strong on the top). If the simulated sampling procedure uses seeds that match the characteristics of the seeds that were actually used, then the sampling procedure only works under conditions of weak geographic constraint (middle panels). The panels on the left show that given the actual sampling conditions, the assumption that sampling depends only on degree will be violated regardless of geographic constraint. The thought experiment behind this plot is something like “did the empirical results of sampling procedure match our theoretical expectations”, and the answer appears to be “no”. I think this is analogous to an experimental setting where, even despite random assignment, the groups end up unbalanced on key covariates.
The authors also plot the coverage of the RDS sample across the geographic area of the study in the plot below:
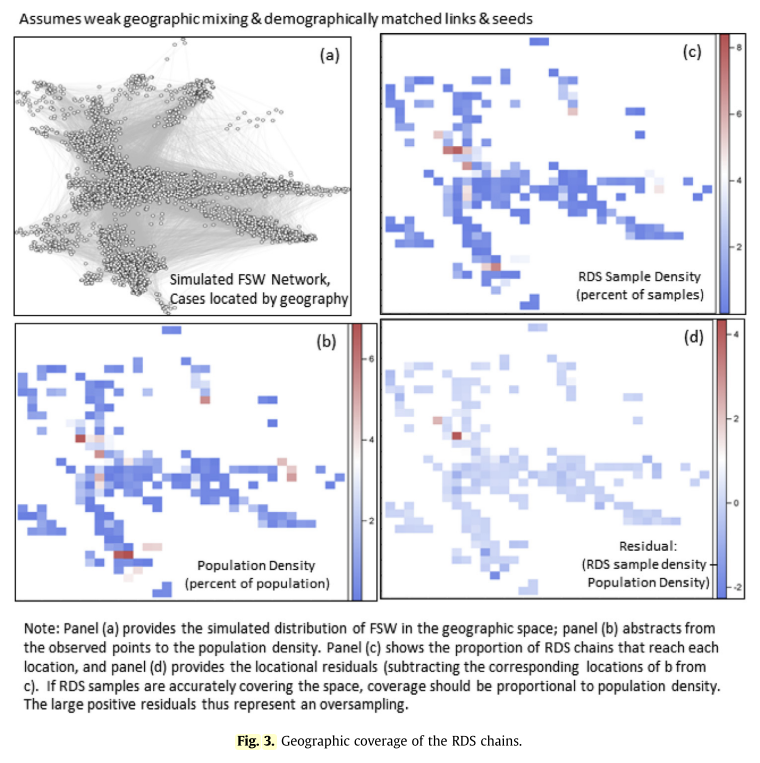
The bottom left plot shows the actual density of the female sex worker population in the region as estimated based on data from the venue-based sample. The plot of the top right shows the sample density resulting from the RDS, and the bottom right panel shows the residual from the two. If the sample achieved even coverage across geography, we would expect the residual plot to be mostly white, or shades of light red and blue. We mostly see this, except for one location which is bright red. This indicates that the RDS procedure yielded substantial oversampling in one central location.
This paper shows clearly the challenges involved with executing an in-person RDS sampling procedure where the population being sampled exhibits spatial clustering. In the absence information about the geographic distribution of the individuals being sampled, it would we difficult to assess whether geography has constrained the sampling procedure, causing violation of a key assumption for inference from RDS.